
“Bperhaps” is not a typo. Read on!
We are over a year into publicly available generative artificial intelligence (GenAI) agents, and even the “experts” are learning more every day. Large Language Models (LLMs) are being updated and workers/artists/students are leveraging the popular platforms more and more every day.
At the same time, these GenAI users are still seeing hallucinations and providing downright crazy answers to their queries.
Take for instance this seemingly simple question:
What word starts with the letter “B” and means “maybe”?
I can’t think of an answer to that off the top of my head, so let’s go to GenAI which can instantly reference vast stores of knowledge.
Here is how Chat GPT handled this question.:

So close! But “perhaps” does not start with the letter “B”. We’ll dive into what happened in a minute, but first let’s give Google’s Bard a try:
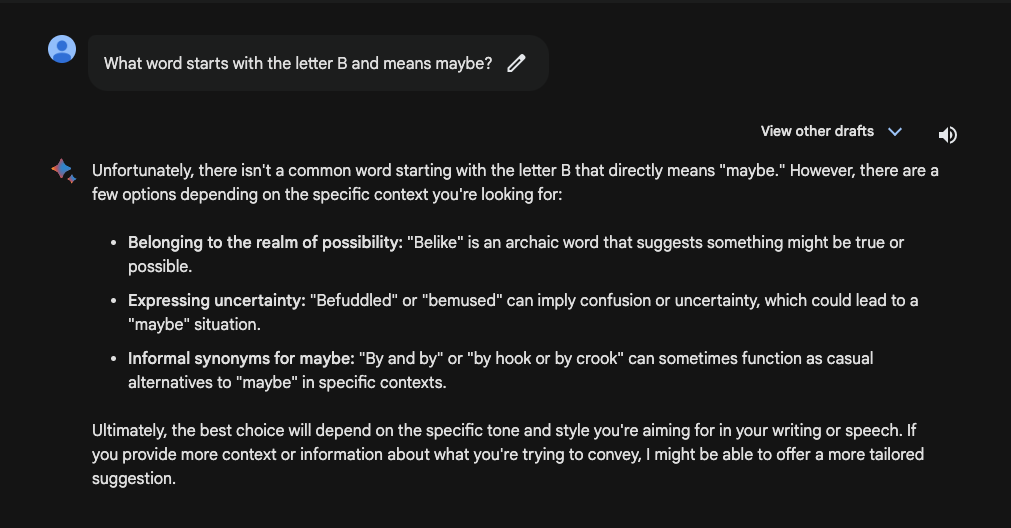
Bard’s answer looks a lot better! It couldn’t find a common word that started with the letter “B”, but it did find a way to answer the question and explain how it got to that answer.
In our effort for fairness, we decided to give ChatGPT another chance:

“Bperhaps!” There it is! Bonus points for creativity, ChatGPT, but a big mark down for accuracy. While making up a word is a clever solution, it does not tell us it is a made-up word or provide any context.
Why ChatGPT couldn’t find a logical answer
Generative AI is truly amazing and these engines have access to tremendous amounts of knowledge, so why couldn’t ChatGPT answer this seemingly simple question?
When there isn’t an obvious, readily accessible answer to a question, they can make things up. At the end of the day, these models can just be next word predictors, similar to what you’ve had on your phone for years. The models aren’t technically framing out real human thought-like processes. The better models can grab some context from what is around them, but they still lack the ability to understand the true context. Context may be based on whatever the last query was about, whether or not it is related to the current query.
In the example above, ChatGPT thought it understood we were looking for another word that meant “maybe”. It missed the critical point that the word should begin with the letter “B” and just predicted the final word: “perhaps”.
Here’s another way to think about it. Imagine I gave you the winners and losers of five random rugby games and asked you to predict the winner of the 6th. You might not realize that one of those matches was incredibly important to the 6th prediction unless I gave you the right context. Maybe one of the first five games had South Africa losing to Vatican City, and the sixth game to predict was South Africa vs. New Zealand. If given the context that Vatican City normally does not have a rugby team, and they recruited players off the street, you might realize this year’s South Africa team would be unlikely to beat New Zealand. In the same way, ChatGPT didn’t know that the “small” detail of beginning with the letter “B” was crucial to the final prediction, simply because it didn’t have enough context.
Why Bard was closer to being “right”
We don’t have any unique insight into the inner workings of Bard, so these are our assumptions and guesses. It seems Bard is working to differentiate itself with some additional prompt engineering and workflows to better address the negative space.
Why do AI systems need to consider the negative space? Put simply, GenAI models need to have enough context to know when to say “I don’t know”. The negative space is the unknown missing context that is relevant to a prompt. Enabling a GenAI based system to accommodate the unknown is key to building trust in its responses. Bard may have built in checks similar to what we did manually for ChatGPT, asking itself “Does this answer the query” before it shares an answer. In this instance, knowing it did not have a simple answer it looked for alternative answers and was able to describe how they fit the query, and fell short of perfect answers.
The importance of custom-built workflows and prompt engineering: helping GenAI “think”
As organizations continue to embrace GenAI, it will become critical that these models do a better job to emulate real human thought processes. Custom-built workflows are a way to make GenAI models “think” in better ways. In our original query to ChatGPT, the model likely “thought” it was utilizing the most critical context when focusing on the need for finding a word that means ‘maybe’ when answering ‘perhaps’. But it didn’t key in on the secondary requirement to ensure the word started with the letter ‘B’. By making the assumption the other elements of the ask were most critical, it failed in answering the original question.
So how can we help large language models key in on important pieces of context? We ask the large language model to break down the task into multiple steps just like a human might approach a problem. As humans, we do this so quickly we may not even realize the steps we’re taking. It is important to ask the large language model to “show your work”, so that we know it’s really thinking through each step to craft its response.
“Talking to Nana”
One of our ClearObject thought leaders likens this to “Talking to Nana”. If you have an aging relative, you sometimes have to help lead their thinking process to get them to fully understand what you are saying.
For instance:
“Nana, do you remember that year we went to Yellowstone?”
“You know that colorful lake we hiked up to?”
“Remember that kid that fell into it?”
“Well, that kid’s parent….“.
The right prompts (questions) are our tools to help focus the LLM, the art is to give the LLM the correct “constrained freedom” so it finds the information we are looking for in the right context. Learning the skills of Prompt Engineering will become increasingly important as AI gains more prominence.
Will GenAI models continue to improve? Bdefinitely!
While ChatGPT and Bard GenAI models are impressive on their own, they often require a decent amount of prompt engineering to be less ~”next word predictors” and more ~”thought process followers”. Some GenAI powered systems, like Bard, seem to already be doing multiple things under the hood before you get an answer, like responding to simple questions such as, “Did this answer match the conditions of the question?” and, “Is this answer insulting to the asker?”.
While off-the-shelf GenAI powered products will continue to improve, you can accelerate the adoption of accurate AI powered systems relevant to your business today by working with prompt engineering experts who can build tailored multi-step workflows for your use cases.